1、Nginx 线上 502、504,到底该查哪一层?
2、Nginx 接口没报错,用户却投诉打不开?这个码叫 499
3、503:Nginx 举白旗,后端全挂还是自己被压垮?
03 | 503:Nginx 举白旗,后端全挂还是自己被压垮?
排障实战系列 · 第 03 篇,Nginx 状态码系列收尾。前两篇拆了 502/504 和 499,这篇收掉最后一个——503。
502 是后端没应答,504 是后端太慢——这俩起码"后端还在"。
503 不一样。它是 Nginx 直接摊牌:Service Unavailable,我现在没法处理请求了。
它最爱在两个时刻爆发:一是后端集体宕机(机房抖一抖、发布翻个车),二是大促抢购,流量一冲,Nginx 自己先顶不住。
503 还特别会滚雪球——用户一见 503 就疯狂刷新,请求量瞬间翻倍,把 Nginx 往死里逼。所以这玩意必须快、准、狠地定位,慢一秒都在放大故障。
一、本质:503 只有两个来源
记住这一句就够了:
503 = 要么后端全挂了(Nginx 没人可转发),要么 Nginx 自己连接数被压垮了(接不进新请求)。
方向完全相反,处理也完全不同。而区分这俩,只需要看一行 error.log。
二、一秒定性:看 error.log 的三个关键词
503 的错误日志会明确告诉你是哪种。盯三个关键词,直接分流:
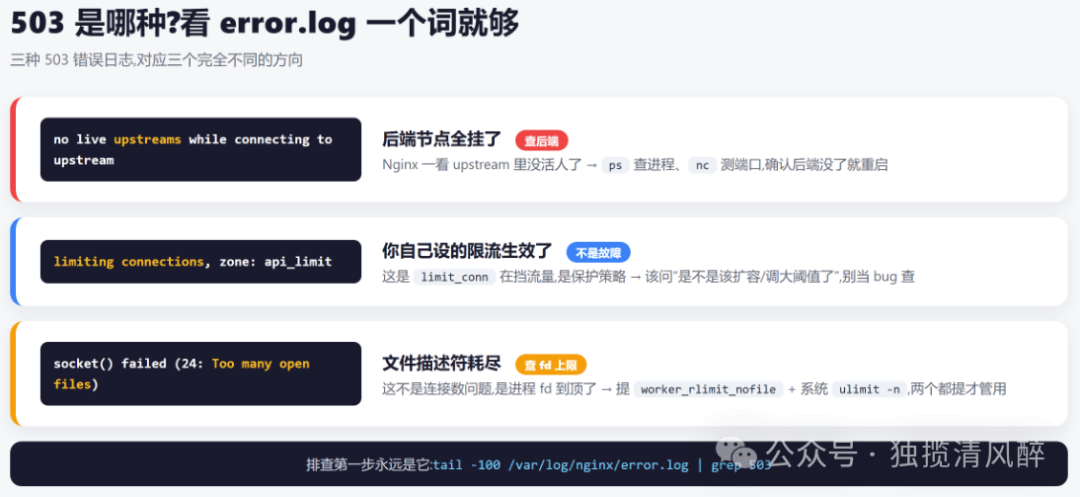
tail -100 /var/log/nginx/error.log | grep 503
- 看到
no live upstreams → 后端节点全挂了 → 往第三节走 - 看到
limiting connections → 你自己设的限流生效了 → 不是故障,该扩容了(见第五节坑三) - 看到
socket() failed (24: Too many open files) → 文件描述符耗尽 → 往第四节走
下面分两条路讲。
三、路线 A:后端全挂(no live upstreams)
这是最好理解的——Nginx 转头一看,upstream 里一个活着的后端都没有,只能返 503。
快速验证后端是不是真没了:
# 后端进程还在吗
ps aux | grep -E "java|php-fpm|node|gunicorn"
# 后端端口还通吗(Nginx 机器上执行)
nc -zv -w 3 10.0.1.10 8080
nc -zv -w 3 10.0.1.11 8080
如果一片 Connection refused,后端确实全挂了。先重启恢复业务,再回头查为什么全挂(通常是发布翻车、配置错误、或依赖的数据库/中间件挂了把后端拖垮)。
顺手补一刀:给 upstream 配上健康检查,别等用户 503 了才发现后端没了。
upstream backend {
server 10.0.1.10:8080 max_fails=3 fail_timeout=30s;
server 10.0.1.11:8080 max_fails=3 fail_timeout=30s;
# 有条件上主动健康检查(nginx_upstream_check_module 或商业版),被动检查靠 max_fails
}
四、路线 B:后端活着,是 Nginx 自己扛不住了
这才是 503 最坑的地方——后端明明好好的,却疯狂 503。新手会去重启后端,发现没用,因为根本不是后端的锅。
这种情况,问题在 Nginx 自己:连接数被打满,或者文件描述符耗尽。
看实时连接水位
# Nginx 实时连接状态(需开启 stub_status)
curl http://127.0.0.1/nginx_status
输出长这样:
Active connections: 980
server accepts handled requests
15234 15234 35000
Reading: 5 Writing: 120 Waiting: 855
盯死 Active connections 这个数。 拿它去比你的 worker_connections,比例就是水位:

Active connections 一旦逼近 worker_connections(比如 980/1024 ≈ 96%),Nginx 就快接不进新连接了——表现就是 503。
紧急扩容
worker_processes auto;
worker_connections 10240; # 从 1024 提到 10240
worker_rlimit_nofile 65535; # 文件描述符上限,必须一起提
nginx -t && systemctl reload nginx
五、三个最容易栽的坑
坑一:别被 worker_connections 的数字骗了
很多人配了 worker_connections 1024 就以为能扛 1024 并发,错。
真实最大并发 ≈ worker_processes × worker_connections ÷ 2~4。为什么要除?因为一个用户请求要消耗不止一个连接:浏览器到 Nginx 一个、Nginx 到后端又一个,浏览器并发请求还要翻倍。
所以 1024 在生产环境基本等于裸奔。起步 4096,稍微像样的业务直接 10240。
坑二:Too many open files 不是连接数问题,是 fd 上限
这个错特别会骗人——看着像连接不够,实际是进程的文件描述符到顶了。这时你把 worker_connections 调再大都没用,因为卡在 fd 上限。
得查的是文件描述符限制:
# 看 Nginx 进程的实际 fd 上限
cat /proc/$(pgrep -f 'nginx: master' | head -1)/limits | grep "open files"
# 看系统级
ulimit -n
解法是两手一起提:Nginx 配 worker_rlimit_nofile 65535,系统级改 /etc/security/limits.conf 或 systemd 的 LimitNOFILE,两个都提才管用,只提一个白搭。
坑三:limit_conn 产生的 503,是保护不是故障
如果你的 error.log 里是 limiting connections,恭喜,这说明你的限流策略生效了——这不是 bug,是你自己设的 limit_conn 在挡流量。
limit_conn_zone $binary_remote_addr zone=api_limit:10m;
# 每个 IP 最多 50 个并发连接,超了直接 503
limit_conn api_limit 50;
高峰期大面积看到这种 503,该问的不是"哪里坏了",而是"是不是该扩容了 / 调大这个阈值了"。别一上来当故障去查,查半天查不出问题。
六、应急:先止血,别在雪崩时排查
503 滚雪球特别快,处置顺序很关键:
| |
|---|
| |
| 紧急提 worker_connections + worker_rlimit_nofile + ulimit,reload |
| 上游网关限流 / 降级关非核心接口 / 临时调大 limit_conn |
原则和 502 那篇一样:先恢复,后排查。 503 雪崩时,每多花一分钟排查,用户刷新带来的流量就翻一倍。先把水位压下来再说。
七、复盘:让 503 再也别"突然"
| |
|---|
| |
| |
| 部署时就把 worker_rlimit_nofile 和系统 ulimit 配到位 |
| |
特别强调一条:503/502 状态码突增、Nginx Active connections 水位,这两个必须配告警。水位到 70% 就该喊你,别等 90% 雪崩了才抢救。
八、写在最后
503 三句话:
- 503 只有两种:后端全挂(
no live upstreams)/ Nginx 自己连接数压垮。看 error.log 一个词就能分。 - 后端活着却 503,99% 是连接数或文件描述符到顶了——查
worker_connections 和 ulimit,不是去查后端。 - limit_conn 产生的 503 是保护不是故障,看到它先想"该扩容了"。
番外:Nginx 状态码四兄弟,到这儿就齐了
502、504、499、503 讲完了,给你一张全家福,贴墙上看:
记住总原则:5xx 全是 Nginx 报的,锅基本都在"Nginx ↔ 后端"这一段;但 503 要多想一层——可能是 Nginx 自己的连接数。
本系列基于个人运维排障笔记整理,命令和场景都经实战。503 你遇过哪种最离谱的?评论区聊聊。
阅读原文:https://mp.weixin.qq.com/s/MGd0j-sog76EoIpkwfedzA
该文章在 2026/6/23 9:31:02 编辑过






 400 186 1886
400 186 1886


