使用 C# + IronOcr,轻松实现图片文字自动识别(OCR)和提取
|
admin 2025年3月3日 22:4
本文热度 2385
2025年3月3日 22:4
本文热度 2385
|
前言
嗨,大家好!
你了解图片文字识别技术(OCR)吗?
所谓的图片文字识别,简单地说,就是识别并提取图片中的文字,简称为 OCR。
近年来,这项技术得到了广泛应用,成为了提升工作效率的利器,想象一下,你需要将某张图片上的文字录入信息库,看着图片一个字一个字的敲打录入,那有该多辛苦!
如果有一个图片文字识别提取工具,点击一下,就能将图片上的文字直接提取出来,这该有多方便!
今天,我们就来聊聊如何使用 C# 实现 OCR 功能,并分享一个详细的例子。
话不多说,我们直接开始吧!
Step By Step 详细步骤
1. 创建项目
创建一个 WinForms 应用桌面程序项目,命名为 "WinFormsOCRSample"
2. 安装 Nuget 包
在项目中添加以下 NuGet 包
<PackageReference Include="IronOcr" Version="2023.5.35" />
<PackageReference Include="IronOcr.Languages.Chinese" Version="2020.11.2" />
注意:如果不装 IronOcr.Languages.Chinese,识别中文时会变成乱码,所以一定要记得装这个包!
3. 设计窗体
接下来,在主窗体上放置两个文本框和一个按钮。
第一个文本框用于输入图片路径,第二个文本框用于显示识别结果,按钮则用于触发 OCR 操作。
如下图:
4. 编写文字自动识别代码
双击窗体上按钮,自动生成按钮单击事件并跳转到代码界面,编写如下代码,留意其中的注释:
using IronOcr;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
namespaceWinFormsOCRSample
{
publicpartialclassfrmImgOCR : Form
{
public frmImgOCR()
{
InitializeComponent();
}
private void btnOcr_Click(object sender, EventArgs e)
{
// 初始化 OCR 引擎
var ocr = new IronTesseract();
// 配置不读取二维码
ocr.Configuration.ReadBarCodes = false;
// 设置语言为简体中文
ocr.Language = OcrLanguage.ChineseSimplifiedBest;
using (var ocrInput = new OcrInput())
{
// 加载图片
ocrInput.AddImage(txtFilePath.Text.Trim());
// 提高识别质量的设置(可选)
ocrInput.Deskew(); // 仅当图片倾斜时使用
// ocrInput.DeNoise(); // 仅当图片包含数字噪声时使用
// 执行 OCR 并获取结果
var ocrResult = ocr.Read(ocrInput);
txtResult.Text = ocrResult.Text; // 显示识别结果
}
}
}
}
5. 运行并测试
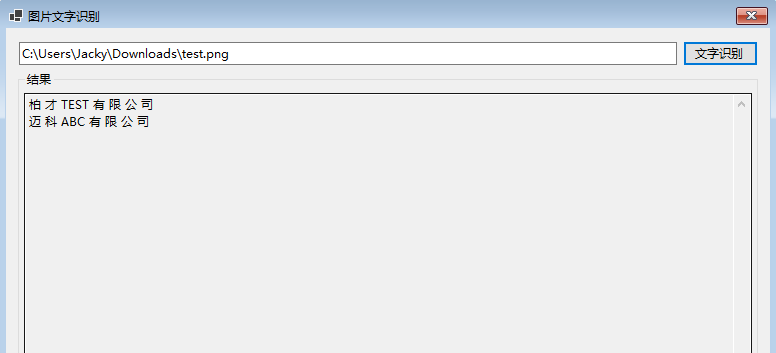
准备一个有文字的图片,如下图:
运行程序,输入图片路径,点击 "文字识别" 按钮,很快地就自动识别出图片上的文字,并输出结果,如下图:
总结
搞定!是不是比想象中简单?只需要几行代码,就让 C# 轻松实现图片文字的自动识别,而且,准确率还不错!
事实上,除了图片上的文字,PDF 也可以轻松识别,你可以在 IronOcr 的官网上解锁更多姿势!
看到这里,你是不是也心动了,赶快也尝试一下吧!
阅读原文:原文链接
该文章在 2025/3/4 11:02:49 编辑过






 400 186 1886
400 186 1886