火了整个春节的DeepSeek,他对AI产品的意义到底是什么?
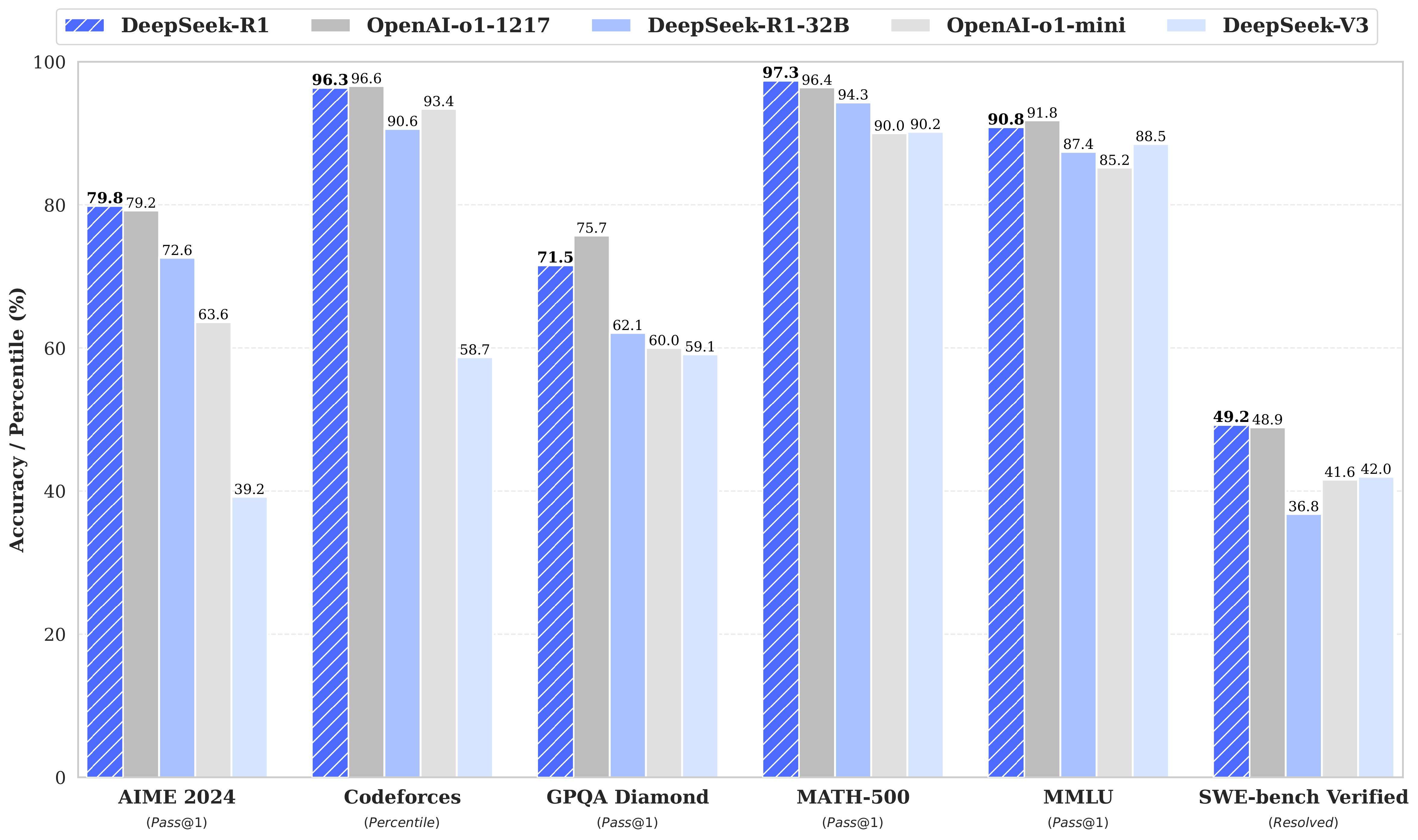
相信春节期间各位的朋友圈一定被DeepSeek“轰炸”了,就算是普通人也获得了一些信息:国内AI取得了巨大突破。 但DeepSeek这次突破到底对一般的互联网从业者有什么帮助,绝大多数人却是一头雾水。 究其原因:Attention is All You need,DeepSeek成了各大自媒体争夺注意力的焦点,所以引起了大量的传播和讨论。 期间,我阅读了至少100篇文章,其中包括官方很多文档,这里的结论是:知道DeepSeek意义的博主故意不说,不懂其内涵的在不停科普,其中还掺杂了大量标题党,所以一时鱼龙混杂。 所以,今天我们整理了过去10天读的100篇文章,得出了一些个人的认知与各位分享,如果内容有误请您指正。 一、效果很好在我印象中DeepSeek-R是第一款直接剑指ChatGPT又取得了不错成绩的国内模型,从数据来看很硬:
所有大模型发布初期多少会有效果夸大部分,但在我亲测使用的情况下:个人评价还是很高的,这其实是令人震撼的。 二、私有化部署在考虑其低成本与开源,并且开放训练手册(学习成本)等特性,新的机会也诞生了:
当然,研发过程中我依旧是最初的观点:研发要着眼于半年后,依赖最强大的模型。 三、成本优势在24年5月,DeepSeek就发布的一款名为V2的开源模型。 其性价比奇高:推理成本约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。 大模型最终效果一定离不开:数据(你们猜数据供应商是不是通用的?)、算法、算力三方纠缠。 区别于其他公司,DeepSeek提出的一种崭新的MLA架构,把显存占用降到了过去最常用的MHA架构的5%-13%。 同时,它独创的DeepSeekMoESparse结构,也把计算量降到极致,所有这些最终促成了成本的下降。 其实,抛开效果很好这一基本元素,私有化部署与成本优势都在其次;但在效果尚可这一前提下,成本优势就有巨大身位领先!
四、创新更多在训练与推理首先,我没有读到DeepSeek在底层模型、技术架构上的创新,更多的信息是围绕训练与推理是优化以及中间件的创新展开。 而DeepSeek的开源模型主要基于其自研的架构,具体细节尚未完全公开,这块暂时无从打开。 但DeepSeek一定利用了已经开源的代码和一些现成的语料,意味着它避免了从头开始研发和收集数据的高昂成本。 五、模型蒸馏是关键而其中最为关键的是通过蒸馏技术,DeepSeek能够从更大、更复杂的模型(如GPT等)中提取出核心的知识和能力,而不是重新从零开始训练一个全新的模型。这种方法可以显著减少需要的训练算力和资源,降低总体成本。 此外,DeepSeek在训练和推理过程中进行了优化,并在中间件方面进行了创新。 六、MoE的成功应用例如,DeepSeek-V3采用了混合专家(MoE)架构,拥有6710亿个参数,每个词元激活370亿个参数。 而你可以将混合专家(MoE)架构 理解为 工程端的优化。 DeepSeek的MoE架构类似于一个由成百上千个领域专家小模型组成的系统。 当用户提问时,系统首先通过意图识别分析问题的核心内容,确定其所属领域。 然后,通过路由系统,将请求引导至最合适的专家小模型,这些小模型会根据各自的专长生成相关答案。 若问题涉及多个领域,多个小模型可能会被激活,生成的答案随后被一个可能稍大点的模型合并成一个完整的回应。 这种设计让DeepSeek能够高效处理多领域问题,保证每个领域的专家模型提供准确答案,同时通过灵活的路由系统提升整体系统的效率和准确性。 七、强化学习DeepSeek在强化学习领域的创新可能集中在优化训练过程和提高效率方面。 通过智能的奖励函数设计和状态空间压缩,DeepSeek可能减少了训练中的计算成本,并加速了策略的收敛。 此外,结合多任务学习,DeepSeek能够在不同任务之间共享知识和经验,从而提升模型的训练效率。 在实际应用中,DeepSeek还可能利用强化学习优化自动决策和资源调度,进一步增强其在复杂环境中的自适应能力。 综上,便是我的一些简单信息整理,有些同学很关注DeepSeek到底如何走向成功的,这里也打个比喻。 一个不恰当的比喻综上,我们可以推理出DeepSeek成功的模糊全貌了,这里做个比喻:
AI应用侧的关注点最终回归到工程应用侧,我们会更遵循拿来主义与实用主义,你如何成功对我一点都不重要,对国内的各位产研同仁来说,DeepSeek最大的意义有两点: 第一,我们拥有了一块国内可以媲美GPT的基座模型,这意义重大!!! 出于安全考虑,医疗、金融等多个领域是明确不允许数据外泄的,但DeepSeek的出现打破了这个魔咒 第二,DeepSeek是开源的,可以私有化部署,并且他大大降低了训练的成本! 曾经,很多公司都在基于API做开发,其原因是首先找不到好的基座模型,其次训练成本高昂,之前所谓的AI应用最佳实践全部是基于成本考虑! 总结一下,站在工程应用的角度,对于基座模型的选择只有三个考虑点:
DeepSeek对技术选型的影响最后,之前最好用的AI产品的两个路径是:
而DeepSeek的成功意味着更多的技术路径有了更多的选择,他大大加快了国内AI应用爆发的效率。 这里有几个关键技术可以应用到AI产品之上,比如你要做一个AI律师,可能需要涉及到以下技术:
提示词 VS RAG VS 微调在AI应用落地中,提示词、RAG(检索增强生成),以及微调是三种常见的技术路径。它们各有特点,适合不同场景需求:
其实从底层逻辑来看,提示词、RAG 和微调的本质都是在影响模型的输入输出权重,只是作用方式和影响深度不同:
三者的差异在于对模型输入输出权重的影响深浅:提示词影响轻微、RAG扩展输入、微调直接改变权重参数。 其中,RAG的底层逻辑相似,都是为优化输入与输出,但微调通过直接调整模型权重,从根本上改变模型能力。 DeepSeek横空出世,对于各个公司技术路径选择会有深刻影响,需要提前布局。 结语从AI产品的工程应用角度来看,DeepSeek的出现为国内AI领域提供了一个全新的技术选择,并为实际落地应用带来了更多可能性。 作为一款具备成本优势、开源且支持私有化部署的基础模型,DeepSeek不仅满足了行业对高性能、大规模模型的需求,还为医疗、金融等对数据安全和合规性要求极高的行业提供了切实可行的解决方案。 然而,尽管DeepSeek在技术上具备显著优势,其在实际工程应用中仍面临诸多挑战: 第一,行业定制化与快速部署:如何将DeepSeek的技术优势与行业特定需求深度结合,是工程实施中的关键课题。 例如,在法律、医疗等领域,AI应用不仅需要高效的知识检索与推理能力,还必须保证生成结果的精准度和可靠性。 这要求开发团队在数据清洗、领域知识注入和模型微调等方面进行大量定制化开发与测试。 其次快速部署能力也是工程应用中的一大挑战。 DeepSeek的私有化部署特性虽然解决了数据安全问题,但在实际落地中,如何实现从模型训练到推理服务的无缝衔接,仍需在工程架构和工具链上进行优化。 并且,在线模型是会迭代的,私有化后就不能迭代了,这个怎么解决还需要思考。 第二,推理性能与成本优化:DeepSeek通过蒸馏技术和MLA架构显著降低了训练和推理成本,但在实际应用中,如何在不牺牲性能的情况下进一步优化推理效率,仍是技术实现中的难点。 例如,在实时性要求较高的场景(如智能客服、实时法律咨询)中,如何通过模型压缩、量化技术或分布式推理来提升响应速度,是工程团队需要重点解决的问题。 此外,如何结合强化学习和混合专家(MoE)架构的优势,实现多任务处理的高效性与准确性,尤其是在多领域联合任务处理时,确保系统的稳定性和性能,也是工程应用中的重要考量。 第三,技术路径的灵活选择:在未来的应用路径选择上,开发者需要根据业务需求灵活运用提示词优化、RAG技术和模型微调等手段。例如: 对于轻量级应用(如创意文案生成),提示词工程可能是最经济高效的选择; 对于需要动态知识更新的场景(如医疗问答),RAG技术可以显著提升生成内容的准确性; 对于高精度、高专业性的任务(如金融分析),模型微调则是不可或缺的手段。 开发者还需在多元化的技术框架中找到最适合自身业务的解决方案,从而提升AI技术的生产力,实现技术向实际业务场景的高效落地。 总结DeepSeek的出现为AI工程应用带来了新的机遇,但其成功落地仍依赖于开发者对行业需求的深刻理解和对技术路径的灵活选择。 未来,AI产品的开发团队需要在定制化开发、性能优化和工程生态构建等方面持续投入,才能充分发挥DeepSeek的技术优势,推动AI技术在实际业务场景中的普及与落地。 通过不断优化工程实现路径,DeepSeek有望成为国内AI应用开发的核心引擎,助力各行各业实现智能化转型。 转自https://www.cnblogs.com/yexiaochai/p/18699686 该文章在 2025/2/7 9:28:32 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886