Tesseract.js:JavaScript 开源 OCR 库?浏览器也可以独立完成文字识别
|
admin 2024年10月10日 22:0
本文热度 3339
2024年10月10日 22:0
本文热度 3339
|
• Github Star: 34.3k[1]
• 官网[2]
Tesseract.js 是一个基于 JavaScript 的开源 OCR(光学字符识别)引擎。

Tesseract.js 是什么?
Tesseract.js 是一个纯 JavaScript 库,它提供了在浏览器中运行 Tesseract OCR(光学字符识别)引擎的能力。由 Google 维护的开源 OCR 引擎,可以识别多种语言的文本,包括自动文本方向和脚本检测,以及提供简单的接口来读取段落、单词和字符的边界框。通过 Tesseract.js 可以在不依赖服务器的情况下,直接在客户端浏览器中处理图像中的文本识别任务。具有以下特点:
• 多语言支持:支持超过 100 种语言的文字识别,覆盖了全球大部分的文字系统,包括英文、中文、法文、德文等。
• 简单易用的 API:提供了简洁的 API,使得实现基本的 OCR 功能变得简单。
• 高度可定制:支持设置识别语言、识别模式等参数,还提供了多页识别、手写字体识别等高级功能。
• 实时识别:支持静态图像识别以及视频流的实时文字识别。
快速开始
安装
安装 Tesseract.js 可以通过 CDN 或 npm/yarn 进行。
npm install tesseract.js
# yarn
yarn add tesseract.js
在浏览器中,可以直接通过 CDN 引入 Tesseract.js,或者在 Node.js 项目中通过 npm 安装。
入门示例
安装完成后,需要引入 Tesseract.js,可以使用 ES6 的 import 语法引入。下面使用 import 语法引入的示例。
// 从 Tesseract 库中解构出 createWorker 函数
import { createWorker } from "tesseract.js";
// 获取按钮元素
const btn = document.querySelector('#btn')
// 为按钮添加点击事件监听器
btn.addEventListener('click', async () => {
// 获取图片元素
const image = document.querySelector('img')
// 创建一个 Tesseract worker,使用中文简体识别模型
const worker = await createWorker('chi_sim')
// 使用 worker 识别图片中的文字
const result = await worker.recognize(image)
// 在控制台输出识别结果
console.log(result.data.text)
// 将识别结果显示在页面上
document.querySelector('#result').innerHTML = result.data.text
// 终止 worker,释放资源
worker.terminate()
})
通过简单的几行代码,实现中文图片的 OCR 文字识别,看效果识别率还是挺高的。
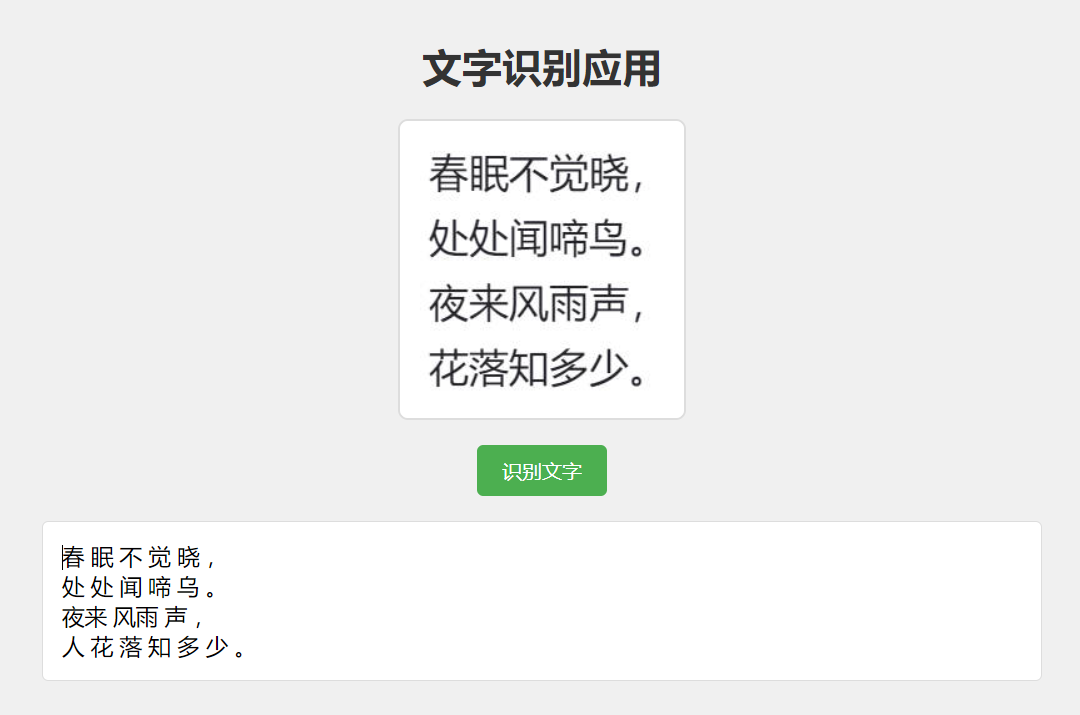
更多功能
上面我们只是简单演示了 Tesseract.js 如何识别中文的。他还是支持更多高级的功能。如多语言识别、自定义识别参数、PDF 输出等。它还进行了多项性能优化,包括文件大小优化、内存使用优化和并行处理支持。
识别效果受到图片质量、文字清晰度、字体样式等多种因素的影响。因此,在实际应用中,你可能需要对图片进行预处理(如裁剪、旋转、缩放、增强对比度等)以提高识别准确率。
总结
Tesseract.js 是一个功能强大、易于使用的 OCR 库,具有广泛的应用场景和广阔的发展前景。希望本期推荐能帮到你!
祝好!
引用链接
[1] Github Star: 34.3k: https://github.com/naptha/tesseract.js
[2] 官网: https://tesseract.projectnaptha.com/
该文章在 2024/10/11 8:59:56 编辑过






 400 186 1886
400 186 1886

